

Marcos Martínez Galindo. Miembro del Joven Consejo Científico del IET. Investigador en IBM Research
En los últimos años, la Inteligencia Artificial (IA) ha ganado mucha popularidad gracias a los llamados grandes modelos de lenguaje (LLM por sus siglas en inglés), como por ejemplo ChatGPT. Estos modelos son entrenados de forma genérica, para poder resolver diferentes tareas y, lo más importante, para hacerlo de una forma amigable para el usuario, por lo que muchas veces nos encontramos con mucho texto en la respuesta que, en según qué casos, implica que tendremos que procesar la salida del modelo antes de poder utilizarla, añadiendo más complejidad a la tarea. Pero el mundo de la IA no se limita únicamente a los LLM, y existen multitud de tecnologías que se pueden utilizar para resolver diferentes tareas, por ejemplo se pueden usar modelos de IA más sencillos, ya sean modelos de lenguaje o no, pero que hayan sido entrenados para resolver únicamente una tarea concreta, lo que aumentará el rendimiento del modelo a la hora de resolver la tarea, será más eficiente al contar con menos parámetros y dará la salida directamente, de una forma más sencilla de procesar.
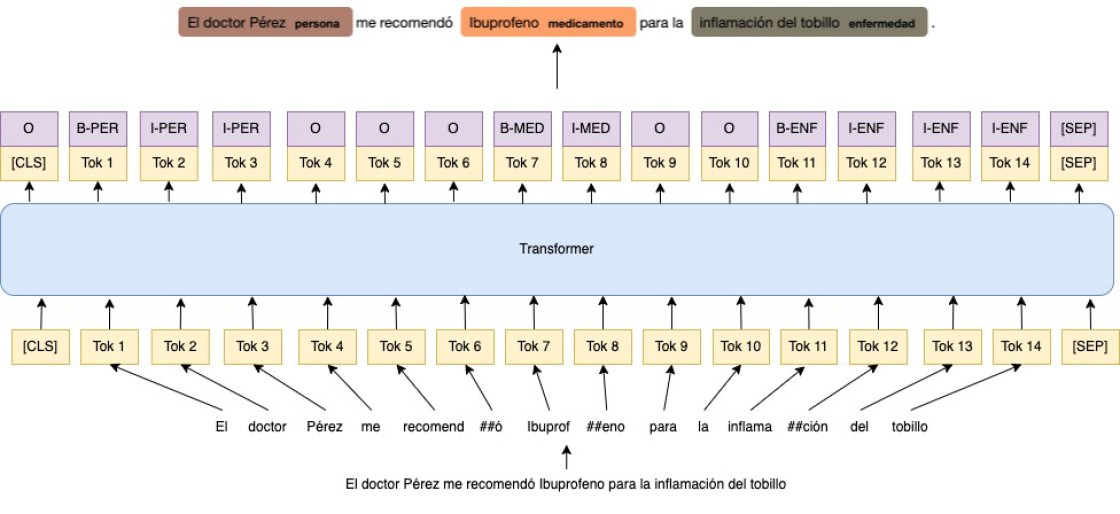
Un ejemplo de esto es el reconocimiento de entidades nombradas (NER por sus siglas en inglés), donde la IA tiene que resolver una tarea a priori sencilla para los humanos, reconocer en un texto entidades que pertenezcan a una clase o categoría concreta, como por ejemplo nombres de personas, organizaciones, no nombres de países y ciudades o, en dominios más específicos, nombres de medicinas, moléculas o enfermedades. NER es una tarea muy importante en el mundo del procesamiento del lenguaje natural, pues permite extraer información de textos y guardarla de forma estructurada, como por ejemplo en bases de datos, permitiendo asá la digitalización de millones de documentos para facilitar su búsqueda y procesamiento.
En los últimos años, desde la salida de los llamados Transformers, los modelos de lenguaje han acaparado las soluciones de prácticamente todas las tareas, incluido NER, y es la tecnología que se encuentra detrás del ya mencionado ChatGPT. Sin entrar en muchos detalles técnicos, y de forma simplificada, el éxito de esta tecnología recae en el llamado mecanismo de atención, que permite a los modelos de IA relacionar todas las palabras que se encuentran en la frase unas con otras, teniendo en cuenta, además, su posición en la frase, y permitiendo encontrar patrones en los textos. Con este mecanismo, el modelo del lenguaje asigna a cada palabra del vocabulario una probabilidad de que sea la siguiente en aparecer en la frase, y basándose en estas probabilidades, el modelo puede aprender de los textos para entender el lenguaje. Esto simplifica el proceso de entrenamiento de los modelos, pues no se necesita procesamiento humano de los textos, simplemente se trata de predecir cuál es la siguiente palabra en la frase, lo que permite poder entrenar los modelos con grandes cantidades de texto y mejorar así su entendimiento del lenguaje.
Una vez se ha entrenado el modelo para entender el lenguaje, lo que se conoce como fase de pre entrenamiento, se puede a˜nadir una capa extra que permita al modelo resolver tareas concretas, como NER, fase que se conoce como ajuste fino. En este caso, el modelo utilizará su entendimiento del lenguaje para crear una representación de cada palabra del texto, y con esta representación podrá decidir si la palabra es parte de una entidad nombrada o no. Pero aquí surge un problema, ¿cómo se entrenan estos modelos? Hasta ahora habíamos dicho que no hacía falta procesamiento humano para entrenar (o mejor dicho, preentrenar) los modelos, pero este caso es más complejo, ya que de alguna forma hay que indicar al modelo que una palabra es una entidad nombrada, y ese conocimiento es algo que tiene que hacer un humano. La solución es simple, se crean conjuntos de datos en los que se etiquetan cientos o miles de frases y se indican las entidades nombradas que aparecen en ellas, pudiendo usar estos conjuntos de datos para entrenar los modelos, lo que se conoce como aprendizaje supervisado. Esto, por supuesto, no es lo ideal, pues es una tarea tediosa y costosa, y limita la cantidad de datos disponibles con los que poder entrenar los modelos, además de que, si se quiere desarrollar un modelo para el reconocimiento de nuevas entidades, o con textos de un nuevo dominio (por ejemplo en el ámbito de la medicina), se requiere de gente experta etiquetando textos para poder entrenar los modelos, lo que no siempre es posible y ralentiza el desarrollo y el avance de esta tecnología.
Aquí entran en juego los llamados modelos zero-shot, que son capaces de reconocer entidades nunca vistas anteriormente, y con las que no han sido entrenados previamente. Esto es un gran avance y permite utilizar esta tecnología en dominios específicos y con nuevas entidades, de una forma rápida y barata, aunque debido a la falta de entrenamiento y la complejidad de la tarea, el rendimiento de estos modelos no es tan bueno como si se entrenasen de forma supervisada. Sin embargo, la posibilidad de usar modelos con entidades nunca vistas es muy interesante para casos de uso reales, y por ello este campo está en constante desarrollo y es una gran rama de investigación, con ejemplos claros como la librería open-source zshot, desarrollada por IBM, que permite utilizar estos modelos de una forma sencilla. Para mejorar el rendimiento de estos sistemas, muchos investigadores proponen aumentar la cantidad de información que el modelo posee sobre las categorías de las entidades a extraer, por ejemplo, proveyendo al modelo de descripciones de las categorías de manera que, por medio del entendimiento del lenguaje que hemos mencionado anteriormente, el modelo pueda relacionar las palabras del texto con estas descripciones, mejorando así el resultado. Aunque esto ayuda a mejorar el resultado, sigue habiendo retos, como por ejemplo proveer al modelo de buenas descripciones, o la necesidad de haber preentrenado el modelo con textos del mismo dominio para poder entender los tecnicismos. Estos problemas se están investigando, y se tratan de solucionar en trabajos como UDEBO (Description Boosting for Zero-Shot Entity and Relation Classification), que propone utilizar modelos de lenguaje adicionales para generar las descripciones de las entidades, de forma que no se necesite a un experto en la materia para generarlas, y Open-BIONER, que preentrena el modelo con grandes cantidades de datos en el ámbito de la medicina, incluyendo algunos etiquetados para NER de forma automática usando ChatGPT, lo que mejora considerablemente el resultado del modelo para textos y entidades relacionadas con la biomedicina.
